发布时间:March 17, 2023, 6:32 a.m.编辑:李佳生阅读(1775)
一、背景
在日常通话、录音等场景进行语音信号采集时,环境中避免不了会存在我们所不希望存在的声音,也就是所谓的噪声。这些噪声混入我们想要采集的语音中,会降低信噪比,严重时则会影响声音的可懂度、可辨识度。因此无论是实时通话、录音还是想对语音做进一步的处理和利用(如语音识别),我们都希望能够将信号中的噪声尽可能去除掉,只留下语音信号,这时就需要使用到降噪算法对信号进行处理,提高语音的质量。
按照噪声与语音的关系,可将噪声分为两种:
1、加性噪声:加性噪声和信号直接不相关,满足加性条件。由噪声和源信号相加得到的。
2、乘性噪声:噪声和信号是相关联的(比如房间的混响),并且往往是在信道传输过程中产生的,所以也叫信号噪声。
按照噪声本身的特征,也可将噪声分为两种:
1、稳态噪声:一直存在且响度、频率分布等特性不随时间变化或变化缓慢。 如手机、电脑之类的设备底噪、电脑散热架的风扇声等。
2、非稳态噪声:噪声的统计特性会随着时间变化而变化,非稳态噪声又分为瞬间噪声(如键盘声、敲击声等)和连续非稳态噪声(babble噪声等)。
目前主流的降噪算法可分为传统降噪算法(谱减法、维纳滤波法...)和基于神经网络的方法,前者一般针对加性、稳态噪声,而后者的应用范围则更广泛些,能力上限与模型种类和大小有着密切关系。在实际工程使用中,也经常采用两者相结合的方式进行语音降噪,传统方法保证兜底的降噪功能,网络来提升降噪的边界,在有限的资源下使模型大小、开销、效果达到一个综合最优的结果。
二、传统降噪算法
1、谱减法
谱减法是最早、也是最为常见的降噪算法之一。基本假设很简单,认为环境噪声为稳态加性,与语音是完全独立不想关的。因此如果已知噪声频谱分布,在采集信号的能量谱上减去其中的噪声部分即可。

由于人耳对语音信号的相位感知不明显,因此谱减是在功率谱上进行的,不考虑相位信息。而相位信息在FFT之后进行保存,iFFT还原信号时,再加入信号之中:
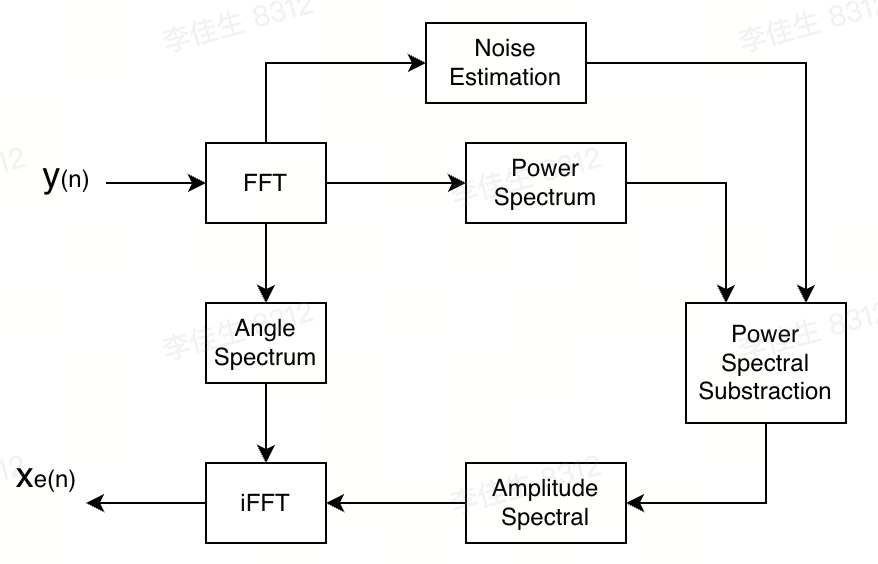
因此噪声估计是谱减法的重要组成部分,噪声估计的是否准确,直接决定了算法效果的好坏,一般通过非语音帧来估计(非语音的平稳信号被认为是背景噪声),所以通常需要加入VAD语音检测模块来判断当前信号的语音、噪声状态,在合适的信号帧进行噪声估计。然而谱减法处理也是有代价的:过多减去噪声谱则会去掉部分语音信号;过少减去则会残留噪声,在背景噪声不平稳时会产生令人反感的音乐噪声(remnant noise,噪声的功率谱是个平均值,当产生波动时,就会减多或者减少,产生与语音信号不相关的随机频率和幅度的窄带信号,这种噪声有音乐听感,因此被称为音乐噪声)。因此许多算法都是在谱减法基础上进行修饰和扩展,以达到使用标准,另外一些机器学习模型也是基于谱减法的基本结构来实现的。
![]() Speech Enhancement using Spectral Subtraction-type Algorithms.pdf
Speech Enhancement using Spectral Subtraction-type Algorithms.pdf
![]() Enhancement of speech corrupted by acoustic noise.pdf
Enhancement of speech corrupted by acoustic noise.pdf
2、自适应滤波器
自适应滤波器的基本原理和思想已经在之前的文章里面讲过(自适应滤波算法),这里不赘述了,主要说下如何应用在语音降噪算法中。
(1) 维纳滤波
在之前文章里面已经介绍过,维纳滤波可以用来对带噪信号进行滤波从而得到期望信号,在语音降噪里面就可理解为针对带噪语音信号的复频谱生成了一个线性估计器,从而估计语音的频谱,该估计值在均方意义上性能最优。维纳滤波方法不会产生音乐噪声,使处理后语音信号听起来更为舒适,但它也假设噪声为平稳信号,因此对于非平稳噪声抑制效果不佳,并且容易造成语音失真。
由于我们假设噪声为平稳、加性噪声,因此认为噪声与语音不想关,于是可套用维纳滤波公式:

从公式中可以看出,维纳滤波降噪的本质还是对噪声(信噪比)的估计。最经典的应用当属webRTC中的降噪算法,包括了一套完整的噪声估计、维纳滤波系数计算、平滑、实际工程化的方法,流程和源代码值得学习。源代码可从官网获取,流程详解可参考系列文章:webRTC语音降噪模块ANS详解
(2) MMSE
基于最小均方误差来估计语音的幅度谱,传统语音降噪算法中具有革命意义的方法,于1984年由Ephraim和 Malah 提出。随后,考虑到人耳对语音频率的非线性感知,他们推导出基于最小均方误差的对数谱估计方法。2001 年,Cohen 提出最优改进对数谱幅度估计方法,它的设计准则是最小化干净对数谱与估计对数谱的误差,首先利用最小值控制递归平均方法估计噪声,再依次估计先验、后验信噪比、语音存在概率,最后计算频谱增益函数估计出干净语音。此后,改进的最小值控制递归平均方法估计噪声被提出,具有估计误差更小且对非平稳噪声跟踪更快的特点,此方法得到了广泛应用。Ephraim and Malah suppression rule [3] (ic.ac.uk)
![]() Ephraim and Malah suppression rule.pdf
Ephraim and Malah suppression rule.pdf
(3) MAP&MLE
基于最大后验MAP(Maximum A Posteriori Estimation)和最大似然估计MLE(Maximum Likelihood Estimation)的原理,根据实际数据更好地估计噪声、相位等参数,从而达到更好的降噪效果。
![]() Maximum-Likelihood spectral amplitude estimator.pdf
Maximum-Likelihood spectral amplitude estimator.pdf
3、子空间
子空间算法将带噪语音信号的向量空间分解为信号子空间与噪声子空间,尽可能保留信号子空间分量且去除噪声子空间的分量,能够在一定程度上抑制噪声,但是子空间法需要对每一帧语音进行奇异值分解或特征值分解,计算代价高,不适用于实时语音降噪。
三、基于神经网络的降噪算法
1、简介
传统的降噪算法都是假设信号是加性、平稳的,因此只能处理平稳或者缓慢变化的背景噪声,而对于非平稳噪声则无能为力。而在硬件平台算力、内存等资源越来越丰富的今天,神经网络越来越受关注,也越来越多地实际应用到音频算法中,包括语音降噪。神经网络在处理平稳和非平稳噪声上,已经表现出非常优秀的效果。
基于神经网络的降噪方法大致可分为三类:基于频谱映射的方法、基于时频掩码的方法、端到端方法。
基于频谱映射的方法:通过网络强大的非线性建模能力来建立带噪语音谱参数与纯净语音谱参数之间的映射关系。
基于时频掩码方法:通过训练神经网络来预测时频掩码,它反映了各个时频单元上对噪声的抑制程度,然后将预测的掩码应用于输入带噪语音的频谱来重构纯净语音信号。常见的时频掩码有理想二值掩码、理想比例掩码、相敏掩码、复比例掩码等。
端到端语音增强:直接处理时域信号,通过模型直接输入带噪语音得到增强后语音信号。
基于深度学习的降噪方法能够取得更好的降噪性能,但是其效果与模型大小强相关,模型大效果好,但是计算复杂度也高。因此对于实时性、CPU 占用率、内存占用率要求较高的平台,模型的资源消耗与最终效果是一种trade-off关系,对现有基于神经网络的降噪技术提出了一定的挑战。在目前的实际工程落地时,经常采用神经网络配合传统算法的结构来实现降噪:传统算法保证大多数情况的效果与鲁棒性,并且降低神经网络的大小,降低算法整体开销,而神经网络则负责扩展降噪效果的边界,针对特定情况的噪声进行消除(比如键盘敲击声等非平稳信号)。
2、模型
(1) RNNoise
经典的第一代降噪模型,主要设计思想是基于传统降噪算法的结构,使用网络来实现VAD、噪声估计、谱减几个部分的功能,是一种传统方法和网络结合的降噪算法。为了减小模型大小和计算量,模型不直接输入信号的能量谱,而是会先计算提取bark频带下的模型子带特征(与mel尺度类似,是更贴近听感的一种频率尺度),并以此作为网络的输入,输出各个子带的调节增益。计算流程如下:
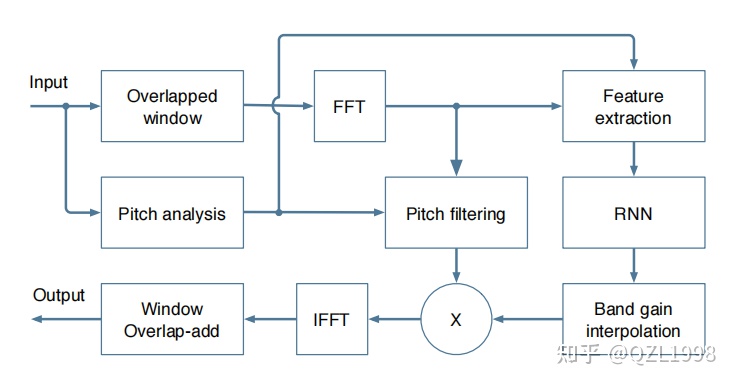
可以看到,相较于传统算法结构,RNNoise又多了一个基频分析和音高滤波的过程,这是由于:模型使用bark子带划分频谱之后,每个子带提取出一个特征,并认为子带之间平滑过渡,这会大大降低频域分辨率。而由于频率分辨率太低,导致模型无法滤除音高谐波之间的噪声,而由于语音信号是周期性、存在谐波的,因此我们可以让音高的谐波通过,但抑制谐波中间的声音(通常是噪声),即梳状滤波。为避免信号失真,梳状滤波器将独立应用于每个频段,其强度既取决于音高相关性,又取决于神经网络计算出的频段增益。
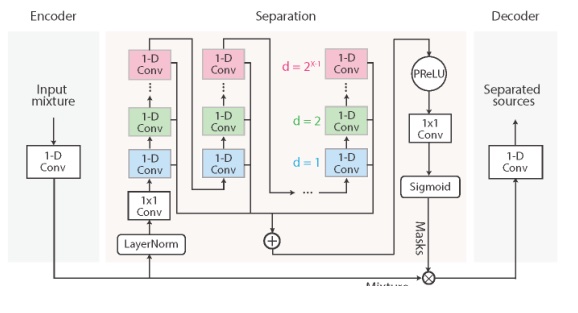
(2) Conv-TasNet
Conv-TasNet是一种端到端的全卷积时域语音分离网络模型。模型先使用线性编码器生成语音波形的表示,再将一组加权函数(掩码)应用于该表示来实现单个说话者的语音分离,最后使用线性解码器将修改后的编码表示反转回时域波形。
![]() Conv-TasNet_Surpassing_Ideal_TimeFrequency_Magnitude_Masking_for_Speech_Separation.pdf
Conv-TasNet_Surpassing_Ideal_TimeFrequency_Magnitude_Masking_for_Speech_Separation.pdf
(3) 待研究
![]() phase_aware_speech_enhancement.pdf 源码链接
phase_aware_speech_enhancement.pdf 源码链接
![]() DUAL-PATH RNN- EFFICIENT LONG SEQUENCE MODELING FOR TIME-DOMAIN SINGLE-CHANNEL SPEECH SEPARATION.pdf 源码链接
DUAL-PATH RNN- EFFICIENT LONG SEQUENCE MODELING FOR TIME-DOMAIN SINGLE-CHANNEL SPEECH SEPARATION.pdf 源码链接
![]() PHASEN- A Phase-and-Harmonics-Aware Speech Enhancement Network.pdf 源码链接
PHASEN- A Phase-and-Harmonics-Aware Speech Enhancement Network.pdf 源码链接
![]() Music Source Separation in the Waveform Domain.pdf 源码链接
Music Source Separation in the Waveform Domain.pdf 源码链接
![]() SUDO RM -RF- EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION.pdf 源码链接
SUDO RM -RF- EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION.pdf 源码链接
![]() DCCRN- Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement.pdf 源码链接
DCCRN- Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement.pdf 源码链接
![]() Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression.pdf 源码链接
Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression.pdf 源码链接
![]() ATTENTION IS ALL YOU NEED IN SPEECH SEPARATION.pdf 源码链接
ATTENTION IS ALL YOU NEED IN SPEECH SEPARATION.pdf 源码链接
![]() Interactive Speech and Noise Modeling for Speech Enhancement.pdf
Interactive Speech and Noise Modeling for Speech Enhancement.pdf
![]() A Simultaneous Denoising and Dereverberation Framework with Target Decoupling.pdf
A Simultaneous Denoising and Dereverberation Framework with Target Decoupling.pdf
![]() DPCRN- Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement.pdf 源码链接
DPCRN- Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement.pdf 源码链接
3、训练数据(持续更新)
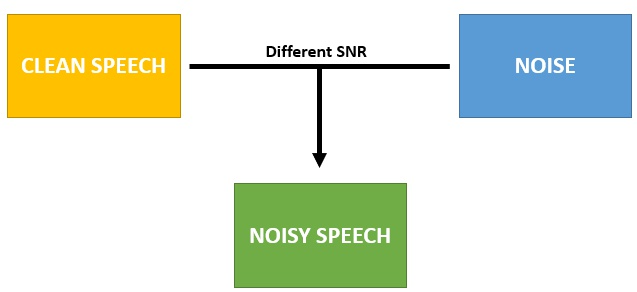
对降噪网络进行训练需要有纯净语音数据和带噪语音数据,开源数据集通常是纯语音和纯噪声两种数据,因此训练时,我们需要将不同语音和不同噪声进行组合,按照不同SNR进行混音得到带噪语音数据。
常用的开源数据集汇总:
语音:
HKUST Mandarin Telephone Speech, Part 1 - Linguistic Data Consortium (upenn.edu)
音频事件&音乐:
GitHub - mdeff/fma: FMA: A Dataset For Music Analysis
GitHub - karolpiczak/ESC-50: ESC-50: Dataset for Environmental Sound Classification
Welcome! | Million Song Dataset
Freesound Audio Tagging 2019 | Kaggle
噪声:
Noise_92-Signal Processing Information Base (SPIB) (ufsc.br)
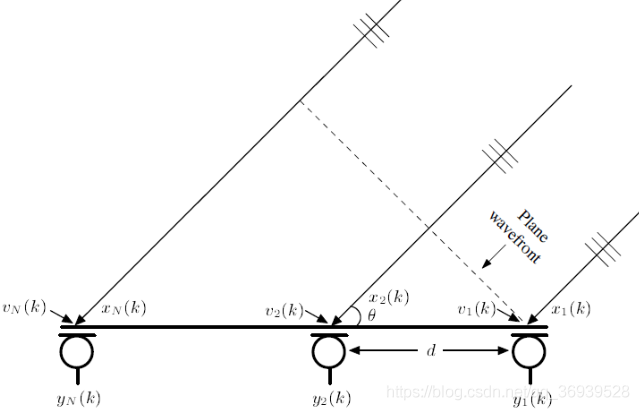
四、多通道(多麦)语音降噪
降噪算法也可以从单通道(单麦)和多通道(多麦)的角度来区分,单通道降噪效果受限并且大部分会对语音造成或多或少的损伤,因此在某些场景下也会采用多麦降噪的方案来提升最终降噪效果和质量。
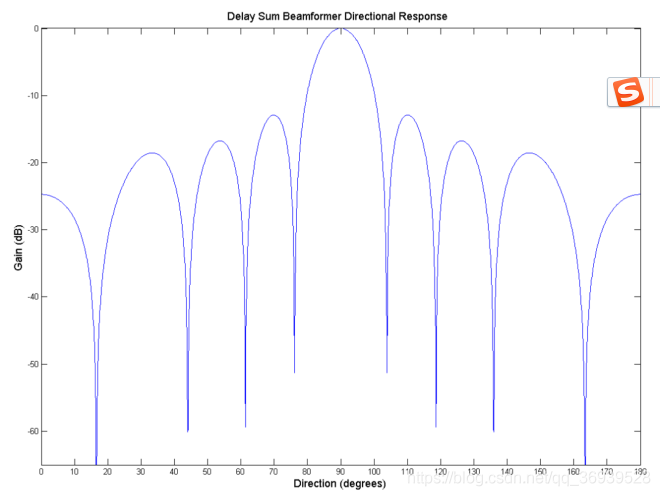
多麦采集可以从不同空间或者方位获得信号,从而更好的判断噪声和语音信号成分。比如目前在手机上经常应用的双麦降噪,即布置一个麦靠近用户发声位置,因此在用户说话时,采集信号的主要成分为语音;而另外一个麦则远离发声位置布置,因此可以认为信号主要为背景噪声。这样就可以更好地判断噪声成分的分布,从而达到更好的语音降噪效果。另外多麦可以组成阵列,通过设计布置位置、距离、数量等,配合波束成型的处理方法使采集信号更接近期望信号。
2158
1775
1592
1501
1312